Contextualized Visual Personalization in Vision-Language Models
Forty-Third International Conference on Machine Learning (ICML), 2026
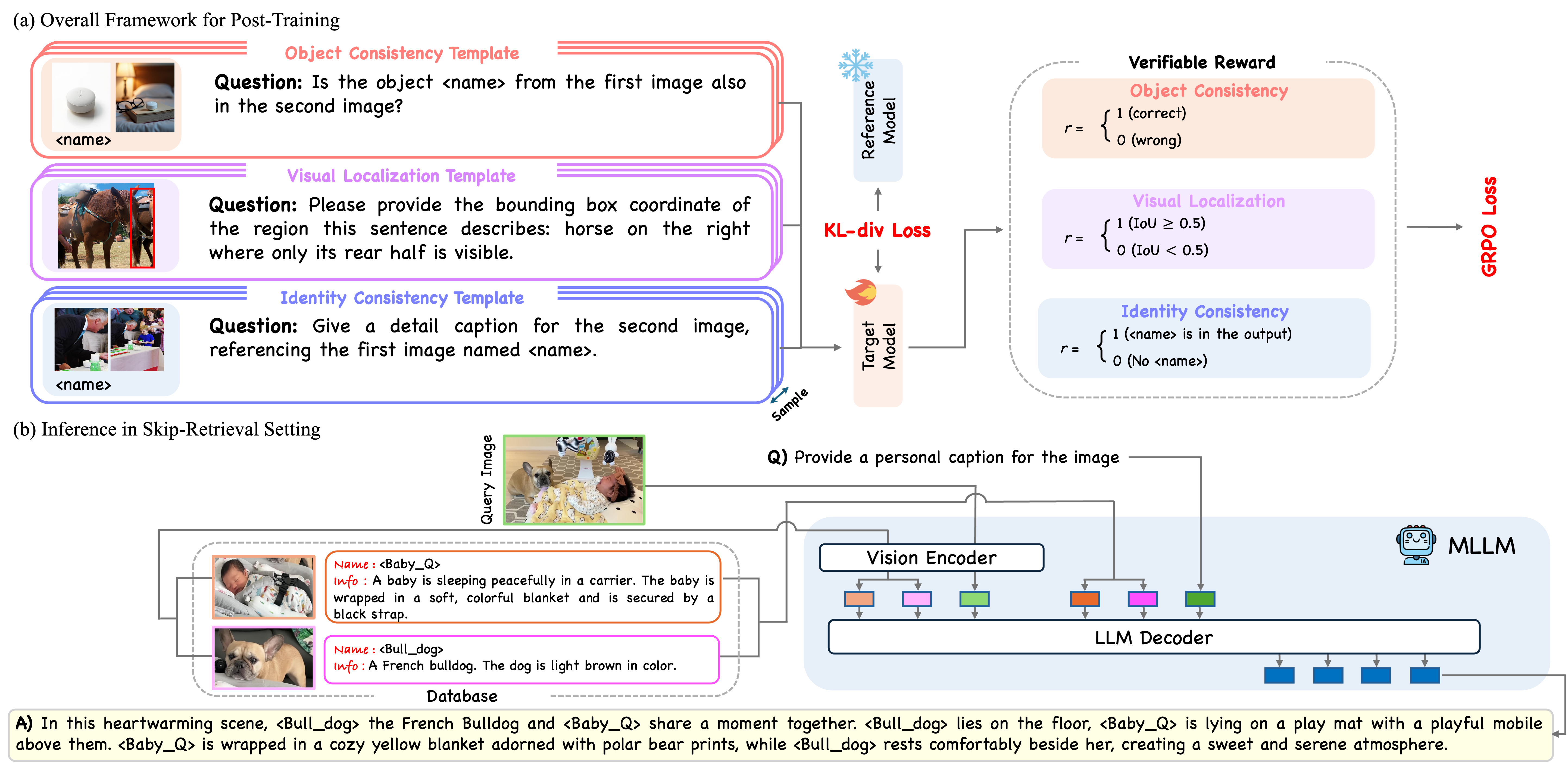
We introduce CoViP, a unified framework for contextualized visual personalization in VLMs, featuring a novel personalized image captioning benchmark, an RL-based post-training scheme, and diagnostic downstream personalization tasks.